Как собрать 6 семантических ядер для 6 информационных проектов за сутки?

Всем привет! Я много раз рассказывал вам, что основной приоритет ставлю на web-студию и контентные проекты, но с популярностью тренингов Романа Пузата многие информационные ниши стали очень конкурентны особенно попсовые типа женская тематика, медицина, некоторая стройка. Но проблема была в том, что я как раз работаю в этих нишах и если собирать ключи по классической схема применяя мозговой штурм, просмотр конкурентов и другие, то практически все запросы будут иметь конкурентность в среднем 6-7 title с прямым ключом топ-10 Яндекса. Вот реально собираешь к примеру 1000 ключей, парсишь и в итоге высеиваешь около 50 нормальных ключей с низкой конкуренцией.
Я пришел к выводу, что надо изменить схему сбора семантики в корне и найти какой-то не стандартный подход. В итоге в голову пришла банальная идея, но в то же время оказалась не проста ее реализация, учитывая, что мы сейчас расширяемся и с нового года запускаем +8 сайтов, а собрать семантику для каждого это реально целое дело особенно когда ты из 1000 ключей высеиваешь 50. Понимаете о чем я? Конечно если у тебя всего 1-2 сайта и ты сам себе вебмастер, то с этим не возникнет проблем, хотя методику, которую я вам сейчас расскажу облегчит жизнь в 100500 раз.
Так вот суть в том, чтобы парсить ключи с сайтов конкурентов с трафиком от 5к в сутки. С этим проблем уже нет, есть куча сервисов для этого, проблема была в том как проверять частоту быстро так как количество ключей переваливает за сотню тысяч, вы только представьте какие это объемы трафика. Думаете поставите парсинг в Кей-коллекторе на сутки и дело в шляпе? Ни хрена! Может если только на месяц=)
Сразу говорю это бредовая идея, здесь нужен проверенный способ. Полазил на форумах где коллеги рекомендовали использовать сервис www.rush-analytics.ru.
Размеры выгружаемых файлов с ключами конкурентов весили по 3мб:
А ключей в файле в среднем по 10-12 тысяч:

Теперь я думаю стало более ясно, что парсить такие объемы коллектором не возможно.
И так далее идем в rush-analytic парсить, сразу говорю процесс регистрации описывать не буду, думаю не маленькие уже. Заходим в систему, открываем вкладку Wordstat и создаем проект:
Внимательно отнеситесь к этой банальной процедуре и на старте выберите регион Россия, а то я как-то быстро щелкал на далее и по умолчанию остался регион Москва. В итоге 500 вылетело в трубу.

Чем еще примечательно использовать этот сервис? Дело в том, что вы можете задать базовую частоту ниже которой ключи не будут парситься, а так же стоп-слова. В информационных сайтах важно писать статьи на запросы не имеющие хвоста к примеру есть запросы типа «Остеохондроз плечевого сустава лечение» или на конце будет «профилактика» так вот нам необходимо отсеять ключи с хвостами. Вручную это делать с десятками тысяч ключей просто физически тяжело, поэтому нужен робот и он здесь есть.

Я стараюсь не заказывать тексты под ключи, которые меньше 400. Многие конечно игнорируют этот момент пытаясь завершить всю семантику по теме, но по моему мнению частоту меньше можно брать в случае, если вы монетезируете сайт каким-то тематическим оффером или планируете это сделать.

В каждой нише существуют свои стандартные стоп-слова к примеру в медицине это будут: лечение, причины, профилактика, диагностика и еще парочка. В скрине я использовал стоп-слова для женского, хотя они пересекаются. Далее запускаете проект и ждете его завершения некоторое время, потом скачиваете exel таблицу на комп.

Полученную таблицу уже сортируете, фильтруете, пробиваете на конкуренцию, потом снова фильтруете и в итоге у вас получиться кристально чистая семантика для информационного сайта. Ну это все и так вам понятно, я бы хотел сконцентрировать ваше внимание на rush-analytics.
Но это еще не все. Умный веб-мастер, свободный веб-мастер. По классика жанра далее приходиться парсить уже готовые ключи, делать кластеризацию и создавать технические задания для копирайтеров. И с этой рутиной задачей справляется наш сегодняшний гость.


В настройках выбираем для какого поисковика делаем задание и выбираем регион.
Честно признаюсь я не совсем понял, что такое «точно», но в тексте сказано, что достаточно пяти, ну и я согласился=)
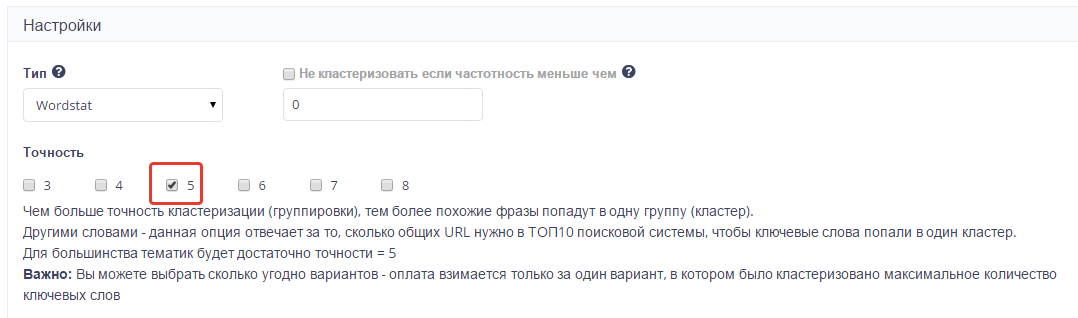
В завершении загружаете файл с ключами и запускаете проект. И все-все ваши проблемы решены, вы получаете уже готовые кластеры, которые раскидываете по ТЗ и загружаете на биржу. Таким образом я буквально за день создал 6 полноценных ядер разбитые на кластеры для 6 информационных сайтом. Используя мой практический пример вы освободите себя от кучи рутиной работы.
И кстати сам сервис www.rush-analytics.ru имеет еще массу инструментов, которые будут полезны для любого веб-мастера или блоггера. На этом у меня все, подписывайтесь на блог и увидимся в следующих статьях.



По сколько страниц планируются у тебя эти 6 сайтов?
По 5 страниц видимо. 6 полноценных ядер.
Валерий, ты то куда лезешь?
Что из статей Борисова уже вылез? [:–_)]
500-600 страниц на сайт. Задача состоит в том, чтобы каждый сайт вышел на 5к трафика в сутки в течение 8 месяцев.
5к трафика – это нехило блин")
Ну, стараемся-)
Что за бред? КК через директ без проблем у 300.000 запросов проверяет частотность за ночь.
Айпи часто банят с КК((
Хз у кого как видимо, 140к ключей за 3 суток проверил. Все виды частотностей, + KEI параметры.
Можно и быстрее, но иногда директ аккаунт блочит:)
В этом вся беда
Посмотрел цены, 0,02 копейки за частотку при моих объемах. Получается за те же 140к ключей, мне пришлось бы выкинуть 2800 деревянных.
Дешевле взять в аренду XML лимиты, и с помощью их прогонять. Сейчас посмотрел, 77к лимитов обойдется в 378 рублей.
Конечно везде нужен разумный подход
какими сервисами пользуешься для сбора ключей?
Advodka
Да, кластеризация для статейников очень весомый аргумент. Больше охват ключей, а значит и НЧ-шек)
Да и копирайтеру легче, видит уже 5-6 подзаголовков (ключей в кластере), и описывает по теме, воды не надо лить")
Теперь тоже беру только частоту не меньше 300-500, а топо нч вышел в топы, а трафу не густо))))
Я лет 5 назад писал статьи в блог под запросы не выше 100=))) послушал просто одного умника![[:-|]](http://jonyit.ru/wp-content/plugins/qipsmiles/smiles/18.png "[:-|]")
Что бы в КК собирать для сотен тысяч запросов частотность нужно запастись: хорошими приватными проксями, большим количеством аккаунтов Яндекса и балансом на антикаптче.
Если все это сложно и затратно, то можно обратится в «Семён Ядрён» и мы соберем частотность для любого Вашего объема, по цене договоримся. О качестве кластеризации семантики писать не буду, лучше один раз увидеть – http://seo-case.com/examples_kernel.html , чем сто раз услышать.
P.S. Вопросы к Антону (автору статьи):
1. Если в группе – 7 запросов с частотностью от 30 до 100 «!», Вы берете в работу такую группу? Или суммарная частотность группы Вас мало интересует?
2. Как Вы считаете достаточно ли тех источников ключей, которые использует rush-analytics (вордстат и подсказки) для полного охвата тематики? Мы ставили эксперименты и у нас получалось максимум 40% от того объема, когда мы использовали все наши источники. Да, это более затратно и трудоемко для парсинга и чистки от мусора, но финальный список запросов того стоит.
1. Если это информационный запрос, то беру в крайнем случае, а если коммерческий плюс еще и транзакционный, то конечно беру.")
2. Я ещё бывает использую базу Пастухова. Дело в том, что когда парсишь информационный запрос, то обычно ключей больше 100 и дополнительные сервисы не нужны так как ты даже под эти ключи статью не напишешь и кластеризацию из них не сделаешь.
А вот коммерческий запрос к примеру купить бетон я буду парсить использую все возможные сервисы.
Ну как-то так.